


آشنایی با دیتافریم
در بخش قبل با ساختمان داده دیتاسری در پانداز آشنا شدیم. دیدیم که دیتاسری بسیار مشابه آرایه تک بُعدی است. اما در دنیای واقعی مجموعه دادههای ما اغلب به صورت جدول هستند (در واقع دو بُعدی هستند) برای این چنین دادههایی کتابخانه پانداز ساختمان داده دیتافریم (DataFrame) را آماده کرده است.
ساخت یک دیتا فریم در پانداز بسیار ساده است و همانطور که در بخش قبل برای ساخت دیتاسری از لیست و دیکشنری استفاده کردیم برای ساخت یک دیتافریم نیز میتوانیم از لیست (اما این بار دو بُعدی) و دیکشنری استفاده کنیم. به مثال زیر توجه کنید:
در مثال زیر با استفاده از دستور DataFrame از کتابخانه پانداز یک دیتافریم به وسیله ورودی دادن یک لیست دو بُعدی (3 در 4) ایجاد کردیم.
import pandas as pd
import numpy as np
df1 = pd.DataFrame([[10, 20, 4, 7],
[2, 8, 15, 4],
[1, 5, 3, 6]])
df1خروجی کد:
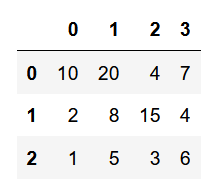
نکته: از آنجایی که فرمت خروجی یک دیتافریم را نمیتوان در این ادیتور نمایش داد از تصویر خروجی استفاده شده است.
مشاهده میکنیم که خروجی در قالب یک جدول بسیار زیبا به ما نشان داده شده است. این جدول دارای نام ستون و نام سطر است. مشاهده میکنیم که نام سطرها و ستونها به صورت پیش فرض از اعداد 0 تا تعداد مورد نظر گذاشته میشود. (برای سطرها چون 3 سطر داریم از 0 تا 2 و برای ستونها چون 4 ستون داریم از 0 تا 4)
دستور ()columns.:
از این دستور برای مشاهده نام ستونهای یک دیتافریم استفاده میشود. به کد زیر توجه کنید:
df1.columnsخروجی کد:
RangeIndex(start=0, stop=4, step=1)مشاهده میکنیم که نام ستونها ما یک RangeIndex است که از بازه 0 تا 4 است. (در واقع از خود 0 تا خود 3)
دستور ()index.:
از این دستور برای مشاهده نام سطرهای یک دیتافریم استفاده میشود. به کد زیر توجه کنید:
df1.indexخروجی کد:
RangeIndex(start=0, stop=3, step=1)دستور ()values.:
از این دستور برای مشاهده دادههای دیتافریم استفاده میشود به کد زیر توجه کنید:
df1.valuesخروجی کد:
array([[10, 20, 4, 7],
[ 2, 8, 15, 4],
[ 1, 5, 3, 6]], dtype=int64)مشاهده میکنیم که خروجی دستور ()values یک آرایه دو بُعدی از جنس نامپای است.
دسترسی به ستونهای یک دیتافریم
برای این که بتوانیم به ستونهای یک دیتافریم دسترسی داشته میتوانیم نام ستون مورد نظر خود را درون [ ] قرار دهیم. به مثال زیر توجه کنید:
در مثال زیر ما ستون 0اٌم را انتخاب کردهایم.
df1[0]خروجی کد:
0 10
1 2
2 1
Name: 0, dtype: int64مشاهده میکنیم که ستون 0اُم از دیتافریم df1 برای ما چاپ شده است. اگر به خروجی توجه کنیم میبینیم که، خروجی ما از جنس دیتاسری است که در سمت چپ نام سطرها قرار گرفته و در سمت راست مقادیر موجود در ستون 0اُم قرار گرفته است.
نکته: از خروجی دستور بالا نتیجه میگیریم که دیتافریم چند دیتاسری به هم چسبیده است. (در واقع ستون 0اُم به تنهایی یک دیتاسری است، ستون 1اُم به تنهایی یک دیتاسری است و ستون 2اُم به تنهایی یک دیتاسری است که این ستونها اگر به هم بچسبند یک دیتافریم را تشکیل میدهند)
دسترسی به چند ستون:
اگر بخواهیم به چند ستون دسترسی داشته باشیم کافیست که نام ستونهای مورد نظر خودمان را درون [ ] بنویسیم. فقط توجه کنیم که باید نام ستونها با کاما از هم جدا شوند. سپس ستونهای نوشته شده را دوباره درون [ ] قرار دهیم. برای این که بهتر متوجه شویم به مثال زیر توجه کنید.
فرض کنید بخواهیم ستونهای 1 و 3 از دیتافریم df1 را انتخاب کنیم داریم:
df1[[1, 3]]خروجی کد:

مشاهده میکنیم که ستونهای 1 و 3 انتخاب شدهاند.
دسترسی به سطرهای یک دیتافریم
برای دسترسی به سطرهای یک دیتافریم از دستورهای [ ]iloc. و [ ]loc. میتوانیم استفاده کنیم.
معرفی دستور [ ]iloc. :
از این دستور برای دسترسی به سطرهای یک دیتافریم استفاده میشود. درون [ ] باید شماره سطر مورد نظر خود را وارد کنیم.
معرفی دستور [ ]loc. :
از این دستور برای دسترسی به سطرهای یک دیتافریم استفاده میشود. درون [ ] باید نام سطر مورد نظر خود را وارد کنیم.
شاید براتون سوال پیش آمده باشه که تفاوت دو دستور بالا دقیقاً چی شد؟ اگر یکبار دیگر توضیح هر دستور را بخوانیم متوجه میشویم که [ ]iloc. نیاز به شماره سطر دارد ولی [ ]loc. نیاز به نام سطر دارد. اما شاید بپرسید که شماره سطر با نام سطر چه تفاوتی میکند. در دیتافریمی که در بالا ساختیم شماره سطر و نام سطر یکی است (چون خودمان تنظیم نکردیم و پانداز به صورت پیش فرض از عدد برای سطر و ستون استفاده کرد) اما در ادامه یاد میگیریم که چگونه برای سطر و ستون نام دلخواه قرار دهیم. در آن صورت باید توجه کنیم که اگر بخواهیم به یک سطر بر اساس شماره آن (که از 0 شماره گذاری میشود) دسترسی داشته باشیم از [ ]iloc. استفاده میکنیم و اگر بخواهیم به یک سطر بر اساس نام آن دسترسی داشته باشیم از [ ]loc. استفاده میکنیم.
در مثال بالا استفاده از دو دستور تفاوتی نمیکند. به کد زیر توجه کنید.
میخواهیم سطر 0 را داشته باشیم داریم.
df1.loc[0]خروجی کد:
0 10
1 20
2 4
3 7
Name: 0, dtype: int64در کد بالا با استفاده از دستور [ ]loc. نام سطر مورد نظر (سطر 0) را درون [ ] نوشتیم و مشاهده میکنیم که سطر مورد نظر ما چاپ شده است.
نکته: اگر به خروجی توجه کنیم میبینیم که به صورت یک دیتاسری چاپ شده است. بنابراین یک دیتافریم را میتوانیم از کنار هم قرار گرفتن چند دیتاسری به صورت سطری نیز در نظر بگیریم.
حال از با استفاده از دستور [ ]iloc. اینکار را انجام میدهیم.
از آنجایی که سطر مورد نظر ما (یعنی سطر 0) شماره سطرش 0 است پس داریم.
df1.iloc[0]خروجی کد:
0 10
1 20
2 4
3 7
Name: 0, dtype: int64مشاهده میکنیم که خروجی هر دو دستور یکسان است.
دسترسی به اعضای یک دیتافریم
برای دسترسی به اعضای یک دیتافریم باید موقعیت (شماره سطر و ستون یا نام سطر و ستون) خانه مورد نظر را درون [ ] به همراه دستور [ ]loc. در صورتی که بخواهیم از نام سطر یا ستون استفاده کنیم، و یا [ ]iloc. در صورتی که بخواهیم از شماره سطر یا ستون استفاده کنیم، مینویسیم. به مثال زیر توجه کنید.
فرض کنید بخواهیم خانه زیر را انتخاب کنیم:
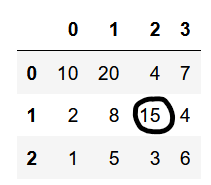
خانه مورد نظر درون سطر 1 و ستون 2 است. پس داریم:
df1.loc[1, 2]خروجی کد:
15مشاهده میکنیم که خانه مورد نظر چاپ شده است.
حال از دستور [ ]iloc. استفاده میکنیم. از آنجایی که خانه مورد نظر در شماره سطر 1 و شماره ستون 2 است پس داریم:
df1.iloc[1, 2]خروجی کد:
15اسلایسرها
ما حتی میتوانیم محدودهای از یک دیتافریم را انتخاب کنیم. اینکار همان اسلایس کردنی است که قبلاً هم در نامپای داشتیم. برای اینکه بتوانیم یک بخشی از یک دیتافریم را انتخاب کنیم دوباره باید از دستور [ ]iloc. یا [ ]loc. استفاده کنیم. به این صورت که بازه مورد نظر برای سطرها را قبل از کاما مینویسیم و با استفاده از یک : شروع و پایان را جدا میکنیم و بعد از کاما نیز بازه مورد نظر خود را برای ستونها مینویسیم و با استفاده از یک : شروع و پایان را جدا میکنیم. یادآور میشوم که اگر بخواهیم از شماره سطرها یا ستونها استفاده کنیم باید از دستور [ ]iloc. استفاده کنیم و اگر هم بخواهیم از نام سطرها یا ستونها استفاده کنیم باید از دستور [ ]loc. استفاده کنیم.
فرض کنید بخواهیم به بخش مشخص شده از دیتافریم زیر دسترسی داشته باشیم.
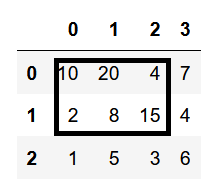 بخش انتخابی در سطر 0 تا 1 و ستون 0 تا 2 است. پس داریم.
بخش انتخابی در سطر 0 تا 1 و ستون 0 تا 2 است. پس داریم.
df1.loc[0:1, 0:2]خروجی کد:
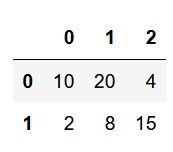 مشاهده میکنیم که دقیقاً بخش مورد نظر ما انتخاب شده است.
مشاهده میکنیم که دقیقاً بخش مورد نظر ما انتخاب شده است.
در کد بالا از دستور [ ]loc. استفاده کردیم. حال بیایید از دستور [ ]iloc. استفاده کنیم. شماره سطر بخش انتخابی از 0 تا 1 است و شماره ستون بخش انتخابی از 0 تا 2 است. پس داریم:
df1.iloc[0:1, 0:2]خروجی کد:
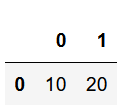
مشاهده میکنیم که خروجی بخش انتخابی ما نیست. (در واقع یک سطر و ستون کمتر است) بنابراین نتیجه میگیریم که اگر از دستور [ ]iloc. استفاده کنیم باید شماره سطر و ستون را یکی بیشتر از محدوده مورد نظر خود وارد کنیم. پس داریم:
df1.iloc[0:2, 0:3]خروجی کد:
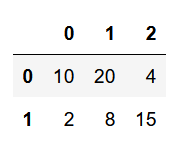 بله مشاهده میکنیم که دقیقاً همان بخش مورد نظر ما شد.
بله مشاهده میکنیم که دقیقاً همان بخش مورد نظر ما شد.
سطر و ستون با نام های دلخواه
در بخشهای قبل مشاهده کردیم که پانداز نام ستونها و سطرها را به طور پیش فرض عدد قرار میدهد. اما ما میتوانیم نامهای دلخواه خود را برای ستونها و سطرها در نظر بگیریم. برای این منظور هنگام ساخت یک دیتافریم از دو آرگومان کلیدواژهایه colmuns برای ستونها و index برای سطرها استفاده میکنیم. به مثال زیر توجه کنید.
در این مثال میخواهیم دیتافریمی داشته باشیم که نمره 4 درس (ریاضی، تاریخ، زیست و فیزیک) برای 3 دانش آموز (علی، فاطمه، احمد) در آن ثبت شده است. پس نمرات ما یک جدول 3 در 4 میشود که نام ستونهای آن، نام 4 درس است و نام سطرهای آن، نام 3 دانش آموز است. داریم:
df2 = pd.DataFrame([[20, 18, 14, 16],
[19, 15, 17, 20],
[15, 16, 18, 19]],
columns=['math', 'history', 'bio', 'physics'],
index=['ali', 'fateme', 'ahmad'])
df2خروجی کد:
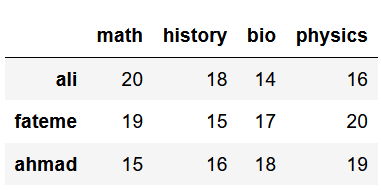
بله مشاهده میکنیم که اینبار دیتافریم ما با نام ستونها و سطرهایی که ما در نظر گرفتیم ساخته شده است.
برای دسترسی به ستونها و سطرهای این دیتافریم نیز دقیقاً مشابه بخشهای توضیح داده شده در بالا عمل میکنیم. برای دسترسی به ستونها فقط کافیست که نام ستون مورد نظر خود را درون [ ] (که جلوی نام دیتافریم نوشته میشود) بنویسیم و برای سطرها نیز اگر بخواهیم از نامها استفاده کنیم از دستور [ ]loc. و اگر بخواهیم از شمارهها استفاده کنیم از دستور[ ]iloc. استفاده میکنیم.
دسترسی به ستونها:




